'Oracle'에 해당되는 글 97건
- 2010.07.07 DB2 테이블 생성 TLVDTALB.GR25TMP0, UPDATE SELECT
- 2010.05.18 DB2 Outer 조인하기.
- 2010.03.30 Where절 날짜조회는 이렇게?!
- 2010.03.09 오라클 Description 조회 및 수정. ( comment on )
- 2009.11.27 락정보
- 2009.11.20 Oracle 11g Improves Partitioning
- 2009.11.20 파티션(Range List Composition Partition)
- 2009.10.14 [오라클10G]table drop후 휴지통비우기
- 2009.10.13 10g RAC 설치 시 발생했던 문제점과 해결 방법
- 2009.10.13 RAC [ Real Application Cluster]
보호되어 있는 글입니다.
내용을 보시려면 비밀번호를 입력하세요.
|
2010/02/27 10:57 |
▶ comment on table 테이블명 is '멋진 테이블';
▶ comment on column 테이블명.칼럼명 is '더 멋진 칼럼';
▶ data dictionary
USER_TAB_COMMENTS
USER_COL_COMMENTS
select * from user_tab_comments
where comments is not null
/
select * from user_col_comments
where comments is not null
/
[SAMPLE#1]
| COMMENT ON COLUMN SAEBIT.ADDITIONCDR_ITEMCOD.TYPE IS '타입'; |
[SAMPLE#2]
select 'COMMENT ON TABLE '||TABLE_NAME||' IS '||COMMENTS||';' from user_tab_comments where comments is not null and table_name in ('PBCATFMT', 'PBCATTBL') select 'COMMENT ON COLUMN '||TABLE_NAME||'.'||COLUMN_NAME||' IS '||COMMENTS||';' from user_col_comments where comments is not null and table_name in ('PBCATFMT', 'PBCATTBL',) |
1. Object 로 조회하기
> SELECT * FROM all_objects
WHERE object_type='TABLE'
AND object_name LIKE '%테이블명 일부%'
2. all_tables 로 조회하기
> SELECT * FROM all_tables
WHERE talbe_name LIKE '%테이블명 일부%'
1. 계정에 대한 LOCK 정보 보기
SELECT USERNAME, ACCOUNT_STATUS,
TO_CHAR(LOCK_DATE,'YY/MM/DD HH24:MI') LOCK_DATE,
PROFILE FROM DBA_USERS;
2. 해당 계정 LOCK 풀기
ALTER USER 계정명 ACCOUNT UNLOCK;
3. 패스워드 몇 번 틀릴 경우 LOCK 되는지
확인
SELECT p.profile, p.resource_name, p.limit
FROM dba_users u, dba_profiles p
WHERE p.profile = u.profile
AND username='modelingworld';
4. 일정 회수이상 로그인 실패시 계정에
LOCK 설정 안되게 설정(보안 고려 필요)
ALTER profile default limit FAILED_LOGIN_ATTEMPTS UNLIMITED;
| ||||||||||
| ||||||||||


No. 22103 (V9.2) RANGE LIST PARTITIONING - ORACLE 9.2 ENHANCEMENT PURPOSE 이 문서는 Oracle 9.2의 새 기능인 Range list partition을 생성하고
Range List Partitioning은 RDBMS V9.2에서 처음으로 소개된 기능이다. Range-List method는 Range 형태로 먼저 데이타를 partition하고 Composite Range-Hash method와는 달리 이 방법은 각 row가 어느
단지 btree 또는 bitmap Local Index 만이 RANGE-LIST type일 수 있다. 아래의 command만이 가능하다. 1) Modify default attributes for table or partition.
The same known restrictions are still available for Range-List
CREATE TABLE empdata
Range-Hash method는 어떤 level에 모든 다른 subpartition들을
Storage 절은 TABLESPACE 절을 제외하고는 partition level로부터 상속받는다. Sample data to load:
[ 생성 / 수정 / 관리 ] set linesize 130;
SELECT TABLESPACE_NAME, PARTITION_NAME, SUBPARTITION_NAME
ALTER TABLE ptnew2
alter table ptnew2
alter table ptnew2 alter table ptnew2
ALTER TABLE ptnew2
SELECT partition_name partition, high_value,
select partition_name, SUBPARTITION_NAME,high_value, subpartition_position from user_tab_subpartitions |
오라클 10g 에서는 table을 drop 하면 테이블명이 이상한 테이블이 남는다.
14:39:03 SQL> select * from tab;
TNAME TABTYPE CLUSTERID
------------------------------ ------- ----------
DEPT TABLE
EMP TABLE
BONUS TABLE
SALGRADE TABLE
STUDENT TABLE
BIN$KoR6DxitQe2IROQYZ/VCeQ==$0 TABLE
BIN$fpGTGSbtRHu8b8WEkLl/mQ==$0 TABLE
BIN$+vzg/bJsTySbtJXGBnsgHw==$0 TABLE
SYSDATETB TABLE
EMP_FTEST TABLE
BIN$6Cen+DdJQW66ybpCCiP2IA==$0 TABLE
CONS_TEST TABLE
12 rows selected.
14:39:08 SQL>
이것을 지우려면 아래의 명령어를 치면 된다
SQL> PURGE RECYCLEBIN
10g는 휴지통 관리를 해서
drop한 후에도 다시 복구 할 수 있다고 한다...
그래서 drop 후에는 쓰레기테이블이 남아있다.
|
"모르는 것이 약이다." 이 말을 참 좋아했는데, 이번 여행동안은 "아는것이 힘이다!!"가 더 중요하다는 걸 알았습니다.
OS에 대해서 거의 무지상태라....설치하면서도 이게 왜 이렇게 되는지, 에러가 나도 왜 나는지...알지 못 해서 책 찾아가면서 하느라 시간이 오래걸렸네요...그럼에도 불구하고 여전히 OS는 무지상태라눈.....
(OS를 차근 차근 공부해야겠어요~~~)
아~~!! 아래 내용이 반말체임을 양해 부탁드립니다...^^;;
===================================================================================================================
VMWare를 이용하여 Oracle Enterprise Linux 기반 Oracle RAC 10g 설치
<?xml:namespace prefix = o />
Ⅰ. 노트북 사양
메모리 2G
하드디스크 160G
OS Windows XP Professional Service Pack2
Ⅱ. 설치 가이드
1. VMWare를 이용하여 Oracle Enterprise Linux 기반 Oracle RAC 10g 설치하기, Vincent Chan
2. Linux, iSCSI 환경에서 Oracle RAC 10g Release 2 클러스터 설치하기, Jeffrey Hunter
Ⅲ. 10g RAC 설치 시 발생했던 문제점과 해결 방법
1. 메모리 : 2G에서도 잘 작동은 하나, 윈도우나 VMWare상의 리눅스 모두 느리다. (많은 인내심이 필요함)
2. VMWare Server 1.0.3 Download : 다운로드 받아서 설치하면 시리얼번호를 입력하라고 나온다…
시리얼 번호를 받기 위해서는 “resister” 회원가입을 해야 한다. 난 혼자 사용할 거라 시리얼번호를 하나만 받았다.
3. 가상 머신 구성
① Virtual Machine Settings : VMWare Server 1.0.3에는 기본으로 floppy disk가 없으므로 삭제 할 필요가 없다
② USB 추가 : Virtual Machine Settings에서 USB 선택하고 ADD를 클릭한다.(소프트웨어를 리눅스 파일에 옮겨야하므로 필요)
③ 추가된 USB는 필요 할 때마다, “Ctrl + D” 혹은 “VM → Removable Devices → USB → 인식된 장치를 체크” 해주면 리눅스에 mount된다.
4. 가상 머신에 Enterprise Linux 설치 할 때 주의 사항
1) Network Configuration : RAC를 설치 하기 전에 궁금했던 부분이었다. IP Address를 어떻게 설정하나..
가이드에 나온 대로 설정하면 된다(가상 IP가 필요한 이유는 “Linux, iSCSI 환경에서 Oracle RAC 10g Release 2 클러스터 설치하기” 참고).
ⓐ 하나의 데이터베이스를 여러 대의 서버가 공유해서 사용하고,
Clusterware & DB설치 할 때, 노드 간에 동일한 데이터를 동시에 액세스할 경우 ping 발생, 특정 노드의
fail 발생 시 정상인 다른 노드로 접속되는 것 등 노드간의 통신이 필요한 경우가 있다. 그래서 IP Address와
Hostname은 field 상황에 맞게 설정하며. 이는 한 노드에서 다른 노드로 원격 접속 설정에 필요하다. 여기서는 테스트
용이므로 임시로 IP Address와 Hostname을 설정한다. (혜은이 생각…. 보충 및 수정 필요)
ⓑ eth0(public network), eth1(interconnect. 노드간의 직접 연결 담당)
2) Selecting System tool in the Package Group Selection : Enterprise Linux Release 4 Update 4의 kernel이 “ELsmp”이므로 “ocfs-2-2.6.9-42.0.0.0.1ELsmp”, “oracleasm-2.6.9-42.0.0.0.1ELsmp”를 선택해야 설치가 된다.
3) 커널 모듈의 종류
① xxx.EL-xx.rpm : for single processor
② xxx.ELsmp-xx.rpm : for multiple processor
③ xxx.ELhugemem- for hugemem
5. 방화벽 비활성화로 설정 : 방화벽이 설정되어 있으면 Oracle Clusterware실행 시 crash(프로세스 실패)된다.
① error message
oac_init:2: Could not connect to server, clsc retcode = 9
a_init:12!: Client init unsuccessful : [32]
ibctx:1:ERROR: INVALID FORMAT
proprinit : problem reading the bootblock or superbloc 22
6. 오라클 사용자의 생성
1) shell 설정
① ksh : 자동 완성 기능 없음. ksh로 설정 시 오라클 사용자 환경 파일은 “.profile”이다.
② bash : 자동 완성 기능 있음. Bash로 설정 시 오라클 사용자 환경 파일은 “.bash_profile”이다.
③ shell 변경 : 변경하려는 계정으로 로그인 → $chsh → [/bin/ksh]:/bin/bash → 재로그인(시스템에 적용됨)
ⓐ 문제점 : 환경 파일에 설정한 환경변수들(ORACLE_BASE, ORACLE_HOME등)을 인식하지 못해서 폴더가 생성되지 않거나 설치 해당 경로를 인식하지 못하는 등의 에러 발생.
ⓑ 해결책 : 환경 파일을 shell에 맞게 구성하거나, 사용자 생성 할 때부터 원하는 shell로 구성한다.
2) “파일시스템 디렉토리 구조의 생성”에서 오타
mkdir –p $ORACLE_BASE/admin
mkdir –p $ORACLE_HOME
mkdir –p $ORA_CRS_HOME
3) oracle 사용자의 shell Limit 설정 : root계정에서 실행
4) Enterprise Liux 소프트웨어 패키지 설치 : VMWare에서 “Ctrl + D”를 눌러서 CD-ROM에서
“use ISO Img”로 설정을 변경해서 CD를 mount한 후, redhat ISO 3번 파일에 필요한 패키지를 설치한다.
5) redhat ISO 3번 CD : ocfs와 oracleasm 패키지 설치와 관련된 파일,
libaio-0.3.105-2.i386.rpm, openmotif21-2.1.30-11.RHEL4.6.i386.rpm 파일이
있다.
7. oracleasm 패키지 설치
1) 설치 순서 : 리눅스 설치할 때 설치가 되나, 설치가 안되었거나 재설치 할 때 참고
oracleasm-support-2.0.3-2 → oracleasm-2.6.9-42.0.0.0.1ELsmp → oracleasmlib-2.0.2-1
<?xml:namespace prefix = v ns = "urn:schemas-microsoft-com:vml" /><?xml:namespace prefix = v />

8. DISPLAY 환경 변수 설정
1) Can’t open DISPLAY error
① 설치 가이드 방법 대로 설정하면 아래 그림과 같은 에러

② 해결 방법
ⓐ method1
rac1]ssh –X oracle@rac2
rac2]export DISPLAY=rac1:0.0
rac2]xclock
ⓑ method2 : method1에서 에러 발생시
rac1]ssh –Y oracle@rac2
rac2] xclock
2) X11Forward error 발생
① X11Forwarding이 활성화되어 있으면 오라클 설치 작업이 실패한다.


② 해결 방법 : X11Forwarding을 비활성화 한다.
è /etc/ssh/sshd.config에서 “X11Forwarding no” 로 설정을 변경한다.( “#X11Forwarding yes” 주석처리)
9. ASM 설정
1)한 노드에서만 ASM 디스크를 생성한다.
2) 새로운 볼륨인식은 모든 노드에서 수행한다.
# /etc/init.d/oracleasm scandisks
10. 파일시스템 마운트
1) 설치 전에 “mount”명령어를 통해서 OCFS2가 마운트 되었는지 확인 해야 한다.
① 마운트가 안 되었을 경우 발생하는 에러(⒜각 노드간의 원격 접속이 안되거나,⒝해당 경로의 permission이 "oracle"로 설정이 안되어 있어도 같은 에러가 발생된다.)

② 마운트가 된 상태 확인
# mount
…
/dev/sde1 on /ocfs type ocfs2 (rw,_netdev,datavolume,nointr,heartbeat=local)
③ 커널 모듈을 로드하고 OCFS2 파일 시스템을 마운트 하는데 필요한 설정이 완료 된 후에 o2cb 플래그 설정 확인
#su root
#chkconfig __list o2cb
o2cb 0:off 1:off 2:on 3:on 4:on 5:on 6:off
⊙ 굵은 글씨는 반드시 "on"으로 설정 되어 있어야 한다.
11.Oracle Clusterware와 Oracle Database 10gR2 설치 실행 경로
1) 설치 가이드대로 할 경우에 "staging"폴더를 생성하지 않았으므로 에러 발생
2)해경방법
① USB에 있는 clusterware와 database 소프트웨어를 oracle폴더로 복사한 후, 이 폴더에 압축을 푼다.
(oracle폴더에는 clusterware, database폴더가 생성된다)
② /u01/app/oracle/clusterware/runInstaller
③ /u01/app/oracle/database/runInstaller
12. Oracle Database 10g R2 설치
1)설치 전 사전 점검 작업 수행
# cd clusterware/cluvfy
# ./runcluvfy.sh stage -pre dbinst -n rac1,rac2 -r 10gR2 -verbose
2)Oracel Database 10g R2 설치 명령
# /u01/app/oracle/database/runInstaller -ignoreSysPrereqs
3)Create Disk Groups : 디스크 그룹 생성
ⓐ 설치 후 v$asm_disk 에서 header_status가 unknown으로 나타난다.
ⓑ 백업/복구 테스트:복구가 제대로 수행 안됨.
② 해결 방법:아직 해결 못함.

⊙ Change Disk Discovery Path Click → '/u01/oradata/devdb/asmdisk1','/u01/oradata/devdb/asmdisk2','/u01/oradata/devdb/asmdisk3'

13. 애플리케이션 리소스의 시작/중단
1) oracle 계정으로 로그인한 후 애플리케이션 리소스를 중단 한 후 시작해야 한다.
srvctl stop instance -d devdb -i devdb1
srvctl stop asm -n rac1
srvctl stop nodeapps -n rac1
srvctl start instance -d devdb -i devdb1
srvctl start asm -n rac1
srvctl start nodeapps -n rac1
⊙ devdb : database name
⊙ devdb1/devdb2 : instance name
⊙ rac1/rac2 : hostname
2) crs관련 디렉토리와 파일의 permission 때문에 nodeapps가 시작 안 됨.
① $ORA_CRS_HOME/crs_1:root:oinstall을 "oracle:oinstall"로 변경
② $ORACLE_HOME/racg:oracle:oinstall을 "oracle:dba"로 변경
③ ocfs/clusterware/ocr:root:oinstall을 :"oracle:oistall"로 변경


3)asm 시작 에러 : $ORA_CRS_HOME에서 "bin, crs, lib"폴더가 root:oinstall로 되어 있었다. 그래서 "oracle:oinstall"로 변경해서 해결함

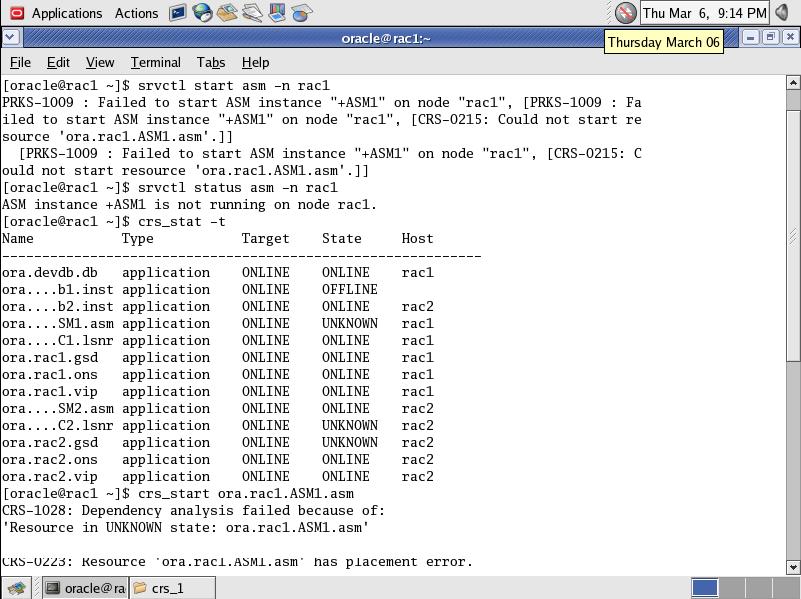
14. Clusterware, database설치 실패 후, 성공적인 재설치를 위해서 모든 파일들을 깨끗하게 정리 해야 한다.
1) 에러 메시지


2) 해결 방법 : 아래 문서들 참고
② CRS 와 10G REAL APPLICATION CLUSTERS
|
* RAC [ Real Application Cluster]
- Application : 클라이언트, 리스너 같은 데이터 베이스로 부터 서비를 받는 모든 것들..
- Cluster : 군집, 집합
: 하나의 데이터 베이스에 여러개의 인스턴스를 띄어 놓아 만들어진 상태
* 싱글 인스턴스

* Instance 가 두 개 일 경우

- 인스턴스는 각 머신에 있다.
- 1번 인스턴스에서 작업을 하다 인스턴스가 죽었을 경우(Fail over)
2번 인스턴스로 투명하게 넘어가서 쓰게 된다. (가용성)
* RAC 를 쓰는 이유?
1] 가용성
2] 로드 발란스
* RAC 구조

- Interconnect : DATAFILE 로 내려 가지 않고 메모리 to 메모리로 전송이 가능하게 해준다.
(Cache Fusion) (OPS 보다 당연히 빠르다.)
: Ethernet + UDP : 가장 보편적으로 사용
- 1Gbit Ethernet : 현재 보편적으로 사용 (초당 125M 정도)
- 10Gbit Ethernet : 향후..
: Infiniband : 향후 ( 초당 2Gbit ~ 96Gbit 까지 적용)
: 전송량이 많을 때 부하가 생긴다.
% ops : 메모리에서 다른 메모리로 읽어질 때 중간에 디스크로 내려썼다가 올라온다.
- 한쪽 클라이언트에서 다른 쪽 클라이언트 까지 같이 설치해 주어야 한다.
- Shared Storage : Raw Device : 가장 보편적 으로 사용 / 쓰기 속도가 좋다 / 관리가 불편
: Clustered File System : 비싸다. 잘 깨진다는 문제가 있다.
: ASM : 점점 기능이 좋아지고 있다.(아직까지는 문제가...
* 클러스터
- OS 클러스터
- ORACLE 클러스터
* 10g RAC 설치 순서
1] 오라클 클러스터를 먼저 설치
2] 오라클 소프트웨어 설치
3] 오라클 ASM 설치 (10g) [OS 클러스터를 안쓸 경우 ASM 을 무조건 설치해 주어야 한다.]
4] 오라클 DB 설치
* RAW Device = > OS 클러스터를 설치 해 주어야 한다.
% 여기서 잠깐!!!!!
|
$ CRS_STAT -t : [Target 컬럼] online 되어져 있어야 다른 쪽 노드로 넘어갈 수 있다. : [State] 현재 상태
$ CRS_STOP -all : RAC 서비스가 멈추어있을 경우에는 stat 를 먼저 확인해 본후 OFF LIne 되었을 경우 $ CRS_START -all : 서비스를 내렸다가(STOP) 다시 올려준다.(START) |

- GCS : Global Cache Sercive [LMS process]
: 인스턴스간 DATA 전송을 담당
: 노드 간의 DATA , 메세지 전송을 관리하는 서비스
-> LMS Process : Global Cache 동기화, 최대 36개까지. (10g R2)
: 데이터 전송이 느릴 때 갯수를 늘려준다.
- GES : Global Enqueue Service [LMD, LCK process]
: Global 하게 Lock 을 관리
: 노드간의 Lock 정보를 요청하고 응답하는 것을 관리 하는 서비스
-> LMD Process : Global enqueue 동기화 (Lcok)
-> LCK Process : Library Cache Lock / Pin , Row Cache Lock 동기화
- CGS : Cluster Group Service [LMON Process ]
: 클러스터의 멤버쉽을 관리하는 서비스
-> LMON Process : Global Lock Monitoring. Process Recovery 등의 작업 수행
(PMON의 Global Version 작업 수행)
[ PMON 의 역활? http://blog.naver.com/kiyoun82/110068928804 ]
- GRD : Global Resource Directory
: Global Resource 의 위치 및 상태를 관리하는 분산 DATABASE
: 모든 BLOCK 의 정보는 BLOCK이 속한 MASTER NODE 의 GRD 에서 관리
: BLOCK 에 최신 정보가 있다.
-> GRD 가 관리하는 정보
: DBA [DATA BLOCK ADDRESS] + Holder 위치 [ holding 하고 있는 위치, emp가 1번에 있니?2번에 있니?없니??]
+ LOCK MODE [Null , Shared , Exclusive] + Role [ Local , Global ] + SCN + PI (Past Image)
% Global - 여러개의 인스턴스를 하나로 쓴다고 하여 Global 이라 표현
* show parameter service
--> 1번 세션확인 : OLTP , YU , BATCH 2번 세션확인 : DB2
--> 1번 세션을 shutdown abort (엔터 강하게!!!!)
--> 1번 세션은 DB down 상태 ----------------> 2번 세션 : OLTP , YU, BATCH
1번 세션에서 넘겨야 한다는 정보는 OCR File 에 들어있다.
% RAC 는 Data file, Control File, Redo log File 이외에, Voting Disk 와 OCR File 까지 필요하다.
- OCR File : 클러스터 구성에 필요한 메타 정보를 가지고 있다.
( -> 작업 중이던 Service가 인스턴스가 죽으면 다른 인스턴스에 넘겨야 한다는 정보가 들어있다)
- Voting Disk : Split Brain 현상을 방지하기 위한 파일
( Split Brain 은 의학용어로 좌뇌와 우뇌의 SYNC 가 맞지 않은 경우, 동기화가 이루어져 있지 않은 경우를 말함)
: 일관된 이미지를 보기 위한 것
: 양 쪽의 인스턴스가 동기화, SYNC 를 맞춰주는 것
* [논리적 / 물리적] 백업을 해주어야 한다.
* OCR FIle 은 오라클이 자동으로 해준다.
* Cahce Fusion
- interconnect 를 통한 효율적인 글로벌 버퍼 동기화 메커니즘.
- Memory to Memory 동기화!!!!!
: Request Node, Master Node, Holder Node 가 Interconnect 를 통해 Block/Message 를 교환 하는 Mechanism

- Request Node : 필요한 특정 블록을 Master Node 의 LMSn 에 요청
: [Request 와 Master 는 메세지만 전송되어진다]
- Master Node : 요청받은 블록(버퍼)의 홀더 노드를 파악한 후 LMSn 에게 요청 노드로의 버퍼 전송을 요청
만일 없을 시에는 Block Grant Message 전달 (직접 ㄷ스크에서 읽어 들이는 권한을 부여]
- Holder Node : 블럭(버퍼)전송이 가능한 경우, 요청 노드로 버퍼를 전송한다.
% 노드가 두개 일 경우!!!
1 - A user 가 EMP 를 읽으려면 1번 instance GRD 를 확인, 없으면 2번 GRD 확인, 없으면 디스크에서 올린다.
2 - 이 때 B user 가 EMP 를 읽으려고 2번 instance 에서 접근시 LMSn 이 interconnect 로 emp 를 넘겨준다.
3 - 이 경우 둘 다 Shared mode 의 Lock 을 갖는다.
4 - B user 가 scott 의 SAL 을 UPDATE 하고 COMMIT 하였을 경우,
-> B user 가 갖고 있던 Shared mode Lock 은 Exclusive 하게 바뀐다.
5 - A user 가 가지고 있던 Shared Mode Lock 은 Null Mode 로 바뀐다.
6 - A user 가 다음 EMP 를 보고자 할 경우에는 UPDATE 된 것을 보아야 한다.(commit 했으니깐...)
[Null Mode 는 다른 노드에서 받아와야 한다는 의미를 내포한다.]
