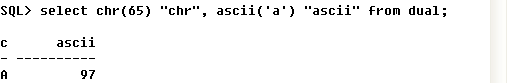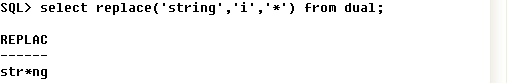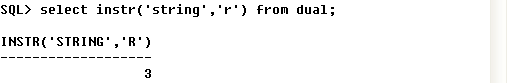SELECT /* DSBIO4OS DSTAXCALZIROLIST51 */
/*+ push_suubq index(세금계산 세금계산_PK ) */
세금계산.번호,
세금계산,발행일자,
세금계산,총액,
세금계산,세액
decode(세금계산.CHOICE1, '고객', TO_CHAR(세금계산.고객_번호),
세금계산.대리점_번호||TOCHAR(세금계산.기타업체_번호)) 고객번호,
세금계산.고객상호
FROM 세금계산
WHERE 세금계산.번호
in (select /*+ user_nl(지로지급, 세금계산_지로입금) */
세금계산_지로집금.세금계산_번호
from 지로지급,세금계산_지로집금
where 세금계산_지로집금. 지로집금_번호 = 지르ㅗ집금.번호
and 지로집금.일자 BETWEEN '&&1_FROM_DATE' AND '&&1_TO_DATE')
AND EXISTS ( select 1 from 고객
where 세금계산.CHOICE1 = '고객'
and 고객.번호 = 세금계산.고객번호
and 고객.지로대상여부 = 'Y'
and 고객.청구사원_번호 = '&&1_SABUN' --19950113
union all
select 1 FROM DUAL
and 세금계산.CHOICE1 = '대리점');
집중사항
1. 데이타는 한번만 Select 해 온다. 죽어도 한번만 select 해 온다.
2. 범위를 일단 줄이는 쪽을 찾아라.
3. 조회할 테이블만 From절에 넣는다.
////오라클의 딕셔너리뷰의table_name,column_name,data_type등등은 대문자로 저장되어있다.
//테이블 정의를 출력
select a.table_name table_name
,b.comments tab_comments
,c.column_id column_id
,c.column_name column_name
,d.comments col_comments
,c.data_type data_type
,decode(c.data_type,'CHAR' ,to_char(c.data_length)
,'VARCHAR' ,to_char(c.data_length)
,'VARCHAR2',to_char(c.data_length)
,'NUMBER' ,'('||to_char(c.data_precision)||','||to_char(c.data_scale)||')'
)data_length
,decode(e.column_name,c.column_name,'Pk') pk_flag
,c.nullable nullable
,c.data_default data_default
from user_tables a
,user_tab_comments b
,user_tab_columns c
,user_col_comments d
,( select f.table_name table_name
,f.column_name column_name
from user_constraints e
,user_cons_columns f
where e.constraint_name = f.constraint_name(+)
and e.table_name = f.table_name(+)
and e.constraint_type(+) = 'P'
)e
where
// a.table_name between 'GFC' and 'GFCZ'
a.table_name like 'GFC%'
and a.table_name = b.table_name
and a.table_name = c.table_name
and a.table_name = d.table_name
and c.column_name= d.column_name
and c.table_name = e.table_name(+)
and c.column_name= e.column_name(+)
order by a.table_name,c.column_id
;
//테이블 프라이머리키 출력(1)
select f.table_name table_name
,f.constraint_name constraint_name
,f.position position
,f.column_name column_name
from user_constraints e
,user_cons_columns f
where f.table_name like 'GFC%'
and e.constraint_name = f.constraint_name(+)
and e.table_name = f.table_name(+)
and e.constraint_type(+) = 'P'
order by f.table_name,f.position
;
//테이블 프라이머리키 출력(2) <- 프라이머리키를 구성하는 칼람들을 한칼람으로 구성(키를 구성하는 칼람갯수는 최고 10개로 생각함)
select f.table_name table_name
,min(f.constraint_name) primary_name
,replace(rtrim(min(decode(f.position,1,f.column_name))||' '
||min(decode(f.position,2,f.column_name))||' '
||min(decode(f.position,3,f.column_name))||' '
||min(decode(f.position,4,f.column_name))||' '
||min(decode(f.position,5,f.column_name))||' '
||min(decode(f.position,6,f.column_name))||' '
||min(decode(f.position,7,f.column_name))||' '
||min(decode(f.position,8,f.column_name))||' '
||min(decode(f.position,9,f.column_name))||' '
||min(decode(f.position,10,f.column_name))),' ',',') column_name
from user_constraints e
,user_cons_columns f
where f.table_name like 'GFC%'
and e.constraint_name = f.constraint_name(+)
and e.table_name = f.table_name(+)
and e.constraint_type(+) = 'P'
group by f.table_name
;
//테이블 인덱스키 출력(1)
select h.table_name
,h.index_name
,h.column_position
,h.column_name
,g.uniqueness
from user_indexes g
,user_ind_columns h
where g.table_name like 'GFC%'
and g.index_name = h.index_name
order by h.table_name,g.uniqueness desc,h.index_name,h.column_position
;
//테이블 인덱스키 출력(2) <- 인덱스키를 구성하는 칼람들을 한칼람으로 구성(키를 구성하는 칼람갯수는 최고 10개로 생각함)
select h.table_name
,h.index_name
,replace(rtrim(min(decode(h.column_position,1,h.column_name))||' '
||min(decode(h.column_position,2,h.column_name))||' '
||min(decode(h.column_position,3,h.column_name))||' '
||min(decode(h.column_position,4,h.column_name))||' '
||min(decode(h.column_position,5,h.column_name))||' '
||min(decode(h.column_position,6,h.column_name))||' '
||min(decode(h.column_position,7,h.column_name))||' '
||min(decode(h.column_position,8,h.column_name))||' '
||min(decode(h.column_position,9,h.column_name))||' '
||min(decode(h.column_position,10,h.column_name))),' ',',') column_name
,min(g.uniqueness) uniqueness
from user_indexes g
,user_ind_columns h
where g.table_name like 'GFC%'
and g.index_name = h.index_name
group by h.table_name,h.index_name
order by h.table_name,uniqueness desc,h.index_name
;
/********************************************************************************************************
*****
테이블 및 인덱스 정보
*********************************************************************************************************
****/
SELECT
CASE WHEN ColumnName = '-' THEN TableName
WHEN ColumnName = 'INDEX INFO' THEN ColumnName
ELSE '-'
END TableName
, CASE WHEN ColumnName = 'INDEX INFO' THEN '-'
ELSE ColumnName
END ColumnName
, ColumnComment
, CASE WHEN ColumnDataType = '-' THEN ''
WHEN ColumnDataType = 'COLUMN DATATYPE' THEN ColumnDataType
WHEN ColumnName = 'INDEX INFO' THEN ColumnDataType
ELSE ColumnDataType + ' (' + CAST(ColumnDataLen AS VARCHAR(10)) + ')'
END ColumnDataType
, IsIdentity, IsNullable
, Collation_name, Definition DefaultValue
FROM (
SELECT
ST.object_Id TableID
, SC.column_id ColumnID
, ST.name TableName
, SC.name ColumnName
, CCM.VALUE ColumnComment
, STY.name ColumnDataType
, SC.Max_length ColumnDataLen
, CASE WHEN SC.is_identity = 1 THEN 'Y' ELSE 'N' END IsIdentity
, CASE WHEN SC.is_nullable = 1 THEN 'Y' ELSE 'N' END IsNullable
, SC.Collation_name
, SD.Definition
FROM sys.tables ST
INNER JOIN sys.columns SC
ON ST.object_id = SC.object_id
INNER JOIN sys.types STY
ON STY.system_type_id = SC.system_type_id
AND STY.user_type_id = SC.user_type_id
LEFT OUTER JOIN ( SELECT major_id, minor_id, VALUE
FROM sys.extended_properties
WHERE class = 1) CCM
ON SC.object_id = CCM.major_id AND SC.column_id = CCM.minor_id
LEFT OUTER JOIN (SELECT parent_object_id, parent_column_id, Definition FROM
sys.default_constraints) SD
ON SC.object_id = SD.parent_object_id AND SC.column_id =
SD.parent_column_id
UNION ALL
SELECT
object_id , -2 , name
, '-' , '-' , '-' , 0 , '-' , '-' , '-' , '-'
FROM sys.tables
UNION ALL
SELECT object_id , 0 , '--'
, 'COLUMN NAME' , 'DESCRIPTION' , 'COLUMN DATATYPE' ,
0 , 'ISIDENTITY' , 'ISNULLABLE' , 'COLLATION_NAME' ,'DEFAULT VALUE'
FROM sys.tables
UNION ALL
SELECT
object_id, -1, OBJECT_NAME(object_id), 'INDEX INFO', NAME, type_desc , 0, idx_info, '-
' , '-' , '-'
FROM ( SELECT D.object_id, IX.NAME, IX.type_desc COLLATE Korean_Wansung_CI_AS_KS AS
type_desc,
CASE WHEN IX.is_unique = 1 THEN 'UNIQUE' + ' , ' ELSE '' END
+ CASE WHEN IX.is_primary_key = 1 THEN 'PK' + ' , ' ELSE '' END
+ ISNULL(MAX(CASE WHEN column_id = 1 THEN D.name + '' +
CASE WHEN IX.is_disabled = 0 THEN '( ASC )' ELSE '( DESC )' END + ' ' END ) , '')
+ ISNULL(MAX(CASE WHEN column_id = 2 THEN D.name + '' +
CASE WHEN IX.is_disabled = 0 THEN '( ASC )' ELSE '( DESC )' END + ' ' END ) , '')
+ ISNULL(MAX(CASE WHEN column_id = 3 THEN D.name + '' +
CASE WHEN IX.is_disabled = 0 THEN '( ASC )' ELSE '( DESC )' END + ' ' END ) , '')
+ ISNULL(MAX(CASE WHEN column_id = 4 THEN D.name + '' +
CASE WHEN IX.is_disabled = 0 THEN '( ASC )' ELSE '( DESC )' END + ' ' END ) , '')
+ ISNULL(MAX(CASE WHEN column_id = 5 THEN D.name + '' +
CASE WHEN IX.is_disabled = 0 THEN '( ASC )' ELSE '( DESC )' END + ' ' END ) , '')
+ ISNULL(MAX(CASE WHEN column_id = 6 THEN D.name + '' +
CASE WHEN IX.is_disabled = 0 THEN '( ASC )' ELSE '( DESC )' END + ' ' END ) , '')
+ ISNULL(MAX(CASE WHEN column_id = 8 THEN D.name + '' +
CASE WHEN IX.is_disabled = 0 THEN '( ASC )' ELSE '( DESC )' END + ' ' END ) , '')
+ ISNULL(MAX(CASE WHEN column_id = 9 THEN D.name + '' +
CASE WHEN IX.is_disabled = 0 THEN '( ASC )' ELSE '( DESC )' END + ' ' END ) , '')
+ ISNULL(MAX(CASE WHEN column_id = 10 THEN D.name + '' +
CASE WHEN IX.is_disabled = 0 THEN '( ASC )' ELSE '( DESC )' END + ' ' END ) , '') idx_info
FROM (SELECT a.object_id, a.name, b.column_id, b.index_id FROM
sys.columns a INNER JOIN sys.index_columns b ON a.object_id = b.object_id AND a.column_id = b.column_id
AND OBJECTPROPERTY(a.object_id, 'IsUserTable') = 1 ) D
INNER JOIN sys.indexes IX
ON IX.object_id = D.object_id AND IX.index_id = D.index_id
GROUP BY D.object_id, D.index_id, IX.NAME, IX.type_desc, IX.is_unique,
IX.is_primary_key, IX.is_disabled
) TIDX
) TBL
ORDER BY TableID, ColumnID
SELECT A.TABLE_NAME, B.COLUMN_NAME, 0 AS INCREMENTS, 0 AS SENSITIVE, DECODE( B.DATA_TYPE, 'VARCHAR2', 12, 'NUMBER', 2, 'CHAR', 1, 'CLOB', 2005, 'BLOB', 2004, 'LONG', -1, 'DATE', 91, 'FLOAT', 6, 12 ) AS COLUMN_TYPE, B.DATA_TYPE AS DATA_TYPE_NAME, B.DATA_LENGTH AS COLUMN_LENGTH, C.COMMENTS AS COLUMN_COMMENT, DECODE(B.NULLABLE,'Y',1,0) AS ISNULLABLE, CC.POSITION AS PRIMARYKEY FROM USER_TABLES A INNER JOIN USER_TAB_COLUMNS B ON B.TABLE_NAME = A.TABLE_NAME INNER JOIN USER_COL_COMMENTS C ON C.TABLE_NAME = A.TABLE_NAME AND B.COLUMN_NAME = C.COLUMN_NAME LEFT OUTER JOIN ( SELECT B.TABLE_NAME, B.COLUMN_NAME, B.POSITION FROM USER_CONSTRAINTS A INNER JOIN USER_CONS_COLUMNS B ON A.CONSTRAINT_TYPE = 'P' AND A.OWNER = B.OWNER AND A.CONSTRAINT_NAME = B.CONSTRAINT_NAME ) CC ON CC.TABLE_NAME = B.TABLE_NAME AND CC.COLUMN_NAME = B.COLUMN_NAME WHERE A.TABLE_NAME = '테이블 이름' ORDER BY B.COLUMN_ID;
-- 제약 조건 조회
SELECT SUBSTR(A.COLUMN_NAME, 1, 15) COLUMN_NAME , DECODE(B.CONSTRAINT_TYPE , 'P', 'PRIMARY KEY' , 'U', 'UNIQUE KEY' , 'C', 'CHECK OR NOT NULL' , 'R', 'FOREIGN KEY') CONSTRAINT_TYPE , A.CONSTRAINT_NAME CONSTRAINT_NAME FROM USER_CONS_COLUMNS A , USER_CONSTRAINTS B WHERE A.TABLE_NAME = '테이블 이름' AND A.TABLE_NAME = B.TABLE_NAME AND A.CONSTRAINT_NAME = B.CONSTRAINT_NAME ORDER BY 1, 2;
미리 규정해 놓은 규칙대로 수행하는 Rule-based optimizer를 사용할것인지, 아니면 좀더 똑똑한 Cost-based optimizer를 사용할것인지 결정하는 것은 매우 중요한 일이다. 아직도 많은 사용자들이 rule-based optimizer를 사용하고 있는 것으로 보이는데 그 이유는 무었일까?
Cost-based optimizer로 변환을 시도한 많은 사용자들이
기대하였던 바와는 달리 성능의 저하를 경험하였을 것이다. 그리고 이것을 tuning할 시간을 갖지 못하거나 새로운
optimizer를 골치아프게 생각하게된 사용자들은 과거의 익숙한 경험인 rule-based optimizer를 고수하게 되는
경향이 있다.
Rule-Based Optimizer란 무었인가?
INIT.ora 에 OPTIMZER_MODE=RULE이라고
정의하던가, 아니면 OPTIMIZER_MODE를 CHOOSE, FIRST_ROWS 또는 ALL_ROWS라고 정의하였어도
ANALYZE를 수행하지 않아서 테이블및 인덱스의 통계치가 없으면 오라클은 rule-based optimizing을 하게 된다.
아니면 SELECT문의 hint로써 RULE을 정의하여도 rule-based optimizer를 사용할 수 있게 된다.
Rule-based optimizer는 다음과 같이 이미 정의되어 있는
규칙에 따른다. 규칙은 테이블내의 로우 갯수라든가 컬럼값의 분포같은 통계치와는 무관하다. Optimizer는 아래 규칙에서 가장
낮은 순위를 우선적으로 선택한다. 예를 들면 쿼리를 하는데 single column index를 이용하는 방법과 single
row by unique or primary key를 이용하는 방법이 가능하다면 optimizer는 순위 4인 single
row by unique or primary key를 선택하게 된다.
Single row by ROWID
Single row by cluster join
Single row by hash cluster with unique or primary key
Single row by unique or primary key
Cluster join
Hash cluster key
Indexed cluster key
Composite key
Single column indexes
Bounded range on index columns
Unbounded range on indexed columns
Sort merge join
MAX or MIN on indexed column
ORDER BY on indexed columns
FULL TABLE SCAN
하지만 이 규칙에서 벗어나는 경우도 있기는 하다. 어떤
경우에는 순위 15위인 FULL TABLE SCAN이 query를 drive하기도 한다. 예를 들면 테이블의 하나가
WHERE절을 가지지 않는 경우에서 이런 현상을 볼수 있다. 한테이블은 유니크 키를 가지고 다른 테이블은 single
column non-unique index를 가지는 두개의 테이블을 조인하는쿼리에서 보통 낮은 순위의 규칙이 drive로
사용된다. 다음 예에서 각 테이블은 acct_no 컬럼을 index로 가지고 있다.
SELECT /*+ RULE */ COUNT(*)
FROM acct , trans, acct_details
WHERE acct.acct_no = trans.acct_no
AND acct.acct_no = acct_details.acct_no
/
HASH JOIN
TABLE ACCESS FULL ACCT_DETAILS
NESTED LOOPS
TABLE ACCESS FULL TRANS
INDEX UNIQUE SCAN ACCT_NDX1
우리는 이러한 규칙 목록을 공부하여야 하고, 이것을 SQL Coding 할때 고려하여야 된다. 규칙 목록이 rule-based optimizer의 전부는 아니다. 이것을 이야기 해보도록 하자.
알아야 할 규칙 (하나)
테이블이 two-column index와
one-column index를 가지고 있고, WHERE절이 이들 3개의 column을 모두 참조한다고 했을때,
one-column index가 unique 또는 primary key가 아닌 한 single index는 사용되지 않는다.
많은 사용자들이 오라클이 두개의 index를 모두 사용하여 index
merge를 할것이라고 믿고 있다. 하나의 테이블에서 index merge는 index가 single column일 경우에만
수행된다. 이것은 cost-based나 rule-based에 모두 적용된다.
Rule-based optimizer가 driving table을
선정할때 다른 join table이 single column nonunique inde를 가지고 있다면 two-column
index를 가진 table이 항상 driving table이 된다.
EMP_NDX1 (DEPT_NO)
EMP_NDX2(EMP_NO, EMP_NAME)
WHERE EMP_NAME = 'HAN'
AND EMP_NO = 1
AND DEPT_NO = 1
인덱스 EMP_NDX2만 사용된다.
알아야 할 규칙 (둘)
WHERE절이 two-column index의 한 컬럼과 single-column index의 컬럼을 사용할 경우에는 single-column index만이 사용된다.
EMP_NDX1 (EMP_NAME)
EMP_NDX2(EMP_NO, DEPT_NO)
WHERE EMP_NAME = 멒URRY?
AND EMP_NO = 1
인덱스 EMP_NDX1만 사용된다.
알아야 할 규칙 (셋)
조건이 같은 경우에는 가장 최근에 생성된 인덱스만을 사용한다.
아래 예에서 같은 날 오후 4시와 5시에 각각 two-column index가 생성되었다. WHERE절이 이들 4개의 컬럼을 모두 참조할때 5시에 생성된 인덱스를 사용하게 된다.
EMP_NDX1 (EMP_NAME, EMP_CATEGORY) created 4pm
EMP_NDX2(EMP_NO, DEPT_NO) created 5pm
WHERE EMP_NAME = 'HAN'
AND EMP_NO = 1
AND DEPT_NO = 1
AND EMP_CATEGORY = 'CLERK'
인덱스 EMP_NDX2만 사용된다.
알아야 할 규칙 (넷)
Three-column(A,B,C) index와
two-column(D,E) index가 있고 아래 예와 같이 WHERE절에서 5개의 컬럼을 모두 사용하는 경우일때, LIKE로
인하여 two-column index를 사용하게 된다. LIKE가 =보다 순위가 낮기 때문이다.
WHERE A=1
AND B=1
AND C LIKE '한%'
AND D=1
AND E=1
인데스(D,E)가 사용된다.
알아야 할 규칙 (다섯)
WHERE절이 사용하는 컬럼이 많이 포함된 인덱스가 사용된다.
WHERE A=1
AND B=1
AND C=1
AND F=1
AND G=1
75% 컬럼이 사용된 인덱스(A,B,C,D)가 선택된다.
65% 컬럼이 사용된 인덱스(F,G,H)는 선택되지 않는다.
알아야 할 규칙 (여섯)
드라이빙 테이블을 결정할때 첫번째 목록이 두번째 목록보다 우선한다.
Full Unique or Primary Key
All columns in index =
Higher % of columns
Not Unique or Primary Key
Most columns in index =
Lower % of columns
순위가 동등한 인덱스 경우에는 rule-based optimizer는 FROM 절에서 마지막에 기술한 인덱스를 선택한다.
일반적인 오해
Oracle8은 rule-based optimizer를 지원하지 못한다......NOT TRUE
Rule-based optimizer에서는 hint를 사용하지 못한다......NOT TRUE
Rule-based optimizer로 잘 tuning된 application은 cost-based optimizer에서도 잘 돌아간다......불행하게도 그렇지 못하다. 추가적인 tuning작업이 필요하다.
Rule-based optimizer의 일반적인 문제
1.
잘못된 드라이빙 테이블
55%
2.
잘못된 드라이빙 인덱스
25%
3.
부적당한 인덱스 사용
15%
4.
기타
5%
1. 잘못된 드라이빙 테이블
Cost-based optimizer에서 rule-base
optimizer로 변경하였을때 잘못된 드라이빙 테이블이 선정되는것을 자주 경험하게 된다. 드라이빙 테이블이 잘못 선정되었을때
그 영향을 알아보기 위하여 다음을 고려하여 보자
TRANS 테이블을 검색하는 문장이 있는데 TRANS의
COST_CENTRE는 ACCT테이블의 ACCT_ID와 같은 의미로 두개의 테이블을 JOIN할수 있게 한다. TRANS
테이블에는 '대구'라는 값을 가진 20,000 이상의 row가 있다. ACCT 테이블에는 ACCT_ID=9의 값을 가진 row가
단 9row뿐이다. TRANS 테이블에는 ACCT_ID=9이고 COST_CENTRE='대구'인 row는 하나도 없다.
ACCT 테이블은 인덱스 ACCT_NDX1(ACCT_ID)를 가지고, TRANS 테이블은 인덱스 TRANS_NDX1(ACCT_ID)와 TRANS_NDX2(COST_CENTRE)가 있다.
다음 문장은 cost-based optimizer로 수행되었고 두개의 table은 모두 ANALYZE되어 있었다.
EXPLAIN PLAN을 보면 ACCT가 드라이빙 테이블이 되었고,TRANS 테이블은 NAD-EQUAL에서 보듯이 두개의 인덱스가 merge되었다.
1 select count(*) from trans a, acct b
2 where a.cost_centre = '대구'
3 and b.acct_id = 9
4 * and a.acct_id = b.acct_id
real: 1977
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 SORT (AGGREGATE)
2 1 NESTED LOOPS
3 2 INDEX (RANGE SCAN) OF 'ACCT_NDX1' (NON-UNIQUE)
4 2 AND-EQUAL
5 4 INDEX (RANGE SCAN) OF 'TRANS_NDX1' (NON-UNIQUE)
6 4 INDEX (RANGE SCAN) OF 'TRANS_NDX2' (NON-UNIQUE)
다음은 테이블의 통계치를 삭제하여 rule-based
optimizer를 적용시킨 것이다. 나는 ANALYZE TABLE ACCT DELETE STATISTICS 와 ANALYZE
TABLE TRANS DELETE STATISTICS를 수행시켰다.
EXPLAIN PLAN을 보면 TRANS를 드라이빙 테이블로
사용하였다. Rule-based에서 인덱스들의 순위가 동등할 경우 FROM 절에 기술된 마지막 테이블부터 선택된다는것을 기억할
것이다. 결과는 cost-based에 비하여 12배의 시간을 필요로 하게 되었다.
1 select count(*) from acct a, trans b
2 where b.cost_centre = '대구'
3 and a.acct_id = 9
4 * and a.acct_id = b.acct_id
real: 19772
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 SORT (AGGREGATE)
2 1 NESTED LOOPS
3 2 TABLE ACCESS (BY ROWID) OF 'TRANS'
4 3 INDEX (RANGE SCAN) OF 'TRANS_NDX1' (NON-UNIQUE)
5 2 INDEX (RANGE SCAN) OF ACCT_NDX1' (NON-UNIQUE)
TRANS 테이블에는 ACCT_ID와 COST_CENTRE
두개의 컬럼이 모두 있다. 문장에서 3번째 ACCT_ID가 ACCT.ACCT_ID가 아니라 TRANS.ACCT_ID로 되었더라면
rule-based optimizer는 TRANS 테이블을 드라이빙 테이블로 선택하지 않았을 것이다.
TRANS.ACCT_ID=9인 경우에 EXPLAIN은 다음과 같았다.
1 select count(*) from trans a, acct b
2 where a.cost_centre = '대구'
3 and a.acct_id = 9
4 * and a.acct_id = b.acct_id
real: 1904
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 SORT (AGGREGATE)
2 1 NESTED LOOPS
3 2 AND-EQUAL
4 3 INDEX (RANGE SCAN) OF 'TRANS_NDX1' (NON-UNIQUE)
5 3 INDEX (RANGE SCAN) OF 'TRANS_NDX2' (NON-UNIQUE)
6 2 INDEX (RANGE SCAN) OF 'ACCT_NDX1' (NON-UNIQUE)
이렇게 하기 위하여 문제는 SQL을 변경하여야 한다는 것이다. Package로 된 SQL을 변경한다는것은 불가능하다. 드라이빙 테이블을 어떻게 변경할 것인가?
우
리가 할수 있는것은 TRANS 테이블에서 COST_CENTRE 인덱스를 삭제하고 ACCT_ID, COST_CENTRE 인덱스를
새로 만드는 것이다. 이 방법은 COST_CENTRE값이 적어도 10,000 rows이상일 경우에 효과가 있을 수 있다.
SQL> 1 select count(*) from acct a, trans b
SQL> 2 where b.cost_centre = '대구'
SQL> 3 and a.acct_id = 9
SQL> 4* and a.acct_id = b.acct_id;
real: 1653
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 SORT (AGGREGATE)
2 1 NESTED LOOPS
3 2 INDEX (RANGE SCAN) OF 'ACCT_NDX1' (NON-UNIQUE)
4 2 INDEX (RANGE SCAN) OF 'TRANS_NDX3' (NON-UNIQUE)
2. 잘못된 드라이빙 인덱스
TRANS 테이블이 두개의 single-column
index를 가지고 있다고 가정하자. TRANS 는 TRANS_NDX2(ACCT_ID)와
TRANS_NDX3(COST_CENTRE) 인덱스를 가지고 있다. Rule-based optimizer입장에서 이 두개의
index는 acess하는데 차이가 없다. 모두 규칙 순위 9 아래이다.
Rule-based optimizer에서 WHERE절의 순서는
중요하다. TRANS 테이블은 600,000 rows를 가지고 있는데 COST_CENTRE='대구'값을 갖는것은 170,000
rows이고, ACCT_ID=9인 것은 단 3개뿐이다. COST_CENTRE가 WHERE절 선두에 기술된 다음 문장은 그
인덱스가 드라이빙 인덱스로 사용되었음을 주목하라. Response time은 4초를 상회하였다.
select count(*) from trans
where cost_centre='대구'
and acct_id = 9;
real: 4225
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 SORT (AGGREGATE)
2 1 AND-EQUAL
3 2 INDEX (RANGE SCAN) OF 'TRANS_NDX3' (NON-UNIQUE)
4 2 INDEX (RANGE SCAN) OF 'TRANS_NDX2' (NON-UNIQUE)
WHERE절의 순서를 보다 적은 row를 가지는 ACCT_ID로 변경하니까 런타임이 25%이상 줄었다. 드라이빙 인덱스 역시 변경되었다.
select count(*) from trans
where acct_id = 9
and cost_centre='대구';
real: 1044
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 SORT (AGGREGATE)
2 1 AND-EQUAL
3 2 INDEX (RANGE SCAN) OF 'TRANS_NDX2' (NON-UNIQUE)
4 2 INDEX (RANGE SCAN) OF 'TRANS_NDX3' (NON-UNIQUE)
3. 부적당한 인덱스 사용
1,000,000 rows를 가진 TRANS 테이블을
생각해보자. 이 테이블에는 BUSINESS_CENTRE, ACCT_ID, TRANS_DATE의 3개 컬럼으로 이루어진 인덱스가
있다. 각각 대략 330,000 rows씩을 가지는 3개의 business center가 있다. 각 ACCT_ID와
TRANS_DATE의 조합은 최대 20 rows정도가 된다. 이 인덱스는 아래 쿼리를 위한 것이었다.
SELECT BUSINESS_UNIT, ACCT_ID, SUM(AMOUNT)
FROM TRANS
WHERE ACCT_ID BETWEEN 1000 AND 1100
AND BUSINESS_UNIT='TIN'
AND TRANS_DATE > SYSDATE - 7
GROUP BY BUSINESS_UNIT, ACCT_ID;
인덱스는 이 문장을 위해서 아주 효과적으로 사용되었다.
어떤 배치 작업이 다음 쿼리를 수행한다면 여기서도 rule-based optimizer는 인덱스를 사용하였을 것이고, 테이블을 full scan하는것보다 훨씬 오랬동안 배치 작업은 끝나지 못했을 것이다.
SELECT SUM(AMOUNT)
FROM TRANS
WHERE BUSINESS_UNIT='TIN'
GROUP BY BUSINESS_UNIT;
그 이유는 UNIT을 위한 330,000 번에다가 인덱스를
또 읽어야 했기 때문이다. 이것은 330,000번의 물리적인 read를 한것과 같다. FULL TABLE SCAN을 하였을 경우
한 블록에 100개의 row가 있다고 했을때 330,000 row를 읽는데는 약 10,000번만 읽으면 족했을것이다.
※ Error관련 내장함수
- SQLCODE : 현재 발생한 오류에 따른 오류 코드를 반환
- SQLERRM : 오라클 오류 코드와 연결된 오류 메시지를 반환
※ 문자열 함수
① ASCII <--> CHAR : ASCII, CHAR로 변환하기
② CONCAT : 조합하기(||와 같은 역할)
③ SUBSTR : 자르기
④ SUBSTRB : 자르기
⑤ INITCAP : 첫글자만 대문자, 나머지글자는 소문자로 변환하기
⑥ UPPER / LOWER : 대문자/소문자로 변환하기
⑦ LPAD / RPAD : 왼쪽채우기/오른쪽채우기
⑧ LENGTH : 문자열의 길이 반환하기
⑨ LANGUAGE : KOREAN_LOREA.KO16KSC5601/AMERICAN_AMERICA.US7ASCII
⑩ REPLACE : 문자 대체하기
⑪ INSTR : 문자열에서 해당문자의 위치 반환하기
⑫ LTRIM / RTRIM : 문자열의 왼쪽/오른쪽 공백 버리기
⑬ TRANSLATE : 문자 대체하기(REPLACE와 같은 기능이나 스트링단위가 아닌 문자단위)
※ 수학 함수
① ROUND : 반올림(해당자리수까지 보여주면서 반올림)
② TRUNC : 버림값
③ MOD : 나눈후 나머지
④ CEIL : 무조건 올림
⑤ POWER : 승수값
⑥ GREATEST : 주어진 데이터중 최대값
⑦ LEAST : 주어진 데이터중 최소값
※ DATE 함수
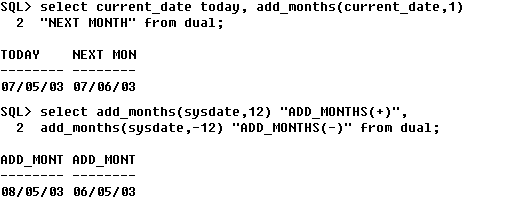
- ADD_MONTHS : 지정된 날짜에 1달을 더함. 만일 결과가 나온 달이 현재 일수보다
작은 일수를 갖고 있는 달로 변경되면 그 달의 마지막 날을 반환
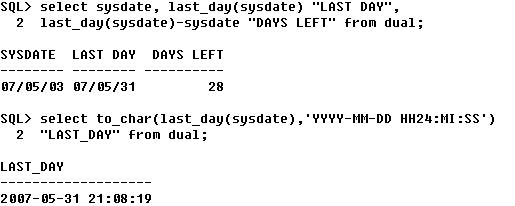
- LAST_DAY : 주어진 달의 마지막 날을 반환
- MONTHS_BETWEEN : 두 날짜 사이의 개월수를 계산. 만일 두 날짜가 그 달의 마지막
이라면 정수를 반환하고 그렇지 않으면 한달을 31로 계산한 분수값을 반환
- NEW_TIME : 사용자가 지정한 시간대에 대한 시간/날짜 값을 반환
- NEXT_DAY : 시작 날짜 다음에 지정된 요일이 처음으로 나오는 날짜를 반환
- ROUND : 월,년도,세기 등과 같이 선택한 날짜 파라미터를 반올림
- SYSDATE : 시스템 날짜와 시간을 DATE형식으로 반환
- TRUNC : 일,월 등과 같이 지정된 날짜 파라미터를 잘라냄
- date + number : date에 number만큼 후의 날짜를 보여줌(일수를 더함)
- date - number : date에 number만큼 전의 날짜를 보여줌(일수를 뺌)
- date1 - date2 : date1에서 date2까지의 총 일수를 보여줌(어떤날짜에서 다른날짜를 뺌)
- date1 + 숫자/24 : date1에서 시간을 더해 날짜를 보여줌(시간에 날짜를 더함)
① MONTHS_BETWEEN : 날짜와 날짜 사이의 개월수를 반환
② ADD_MONTHS : 날짜에 개월수를 더한 일자를 반환
③ NEXT_DAY : 해당일 다음에 오는 특정 요일을 반환
④ LAST_DAY : 지정한 달의 마지막날 반환
⑤ SYSTEM시간
※ 변환 함수
① TO_CHAR : DATE형, NUMBER형을 문자형으로 변환
② TO_NUMBER : 문자를 숫자형으로 변환
③ TO_DATE : 날자 형태의 문자열을 format에 맞게 날짜 형식으로 변환
to_date('" + ls_refill_date2 + "235959','yyyymmddhh24miss') "
④ NUMBER와 DATE를 문자타입으로 변환
⑤ TO_TIMESTAMP : 문자열을 timestamp형식으로 변환
⑥ NVL : null일때 0을 보여줌
⑦ DECODE : default 반환, 디폴트가 없는 경우에는 null값을 반환. 반환하는 값은 최초의
result와 같은 데이터타입(if..then..else기능을 구사하는 유용한 함수)
⑧ NULLIF : 결과값이 동일하면 null, 그렇지 않으면 첫번째 인자값 반환
⑨ NVL2 : 첫번째 인자값이 null이 아니면 두번째 인자값, null이면 세번째 인자값 반환
* 오라클의 환경변수 값 구하기
select userenv('language') "lanugage",userenv('sessionid') "sessionid"
from dual;
※ 그룹 함수
① COUNT : 행의 개수를 구함
② AVG : 평균을 구함
③ SUM : 합계를 구함
④ MIN : 최소값을 구함
⑤ MAX : 최대값을 구함
⑥ STDDEV : 표준편차를 구함
⑦ VARIALCE : 분산을 구함
⑧ VSIZE : 어떤값의 바이트수를 구함
4 년 전에 어느 손해보험 회사에서 차세대 프로젝트를 진행할 때의 일이다. 갑자기 본사에서 전화가 와서 손해보험사의 직원이 프로젝트에 참여 중인 사람들이 엔코아 컨설팅 직원이 맞느냐고 확인하더라는 것이다. 무슨 일인가해서 그쪽 업무 담당자에게 문의해보니, 오라클 DBMS를 사용하면서 계약일자, 사고발생일자 등의 날짜 타입의 속성을 왜 Varchar2(8)을 사용 안하고, Date 타입을 사용하라는 말에 어이가 없어 엔코아 직원들이 맞는지 물었다는 것이다.
필자가 왜 날짜 타입의 속성을 Varchar2(8)을 사용해야 하냐고 물으니,
1) 본인은 이제까지 프로젝트를 하면서 Date 타입을 사용한 적이 한번도 없었고 2) 대용량 데이터베이스 솔루션 1에 Date 타입보다 Varchar2(8)이 Like 연산자를 사용하는데 유리하다고 쓰여 있으니 그렇게 사용해야 한다고 하면서, 이번 프로젝트에 들어온 엔코아 컨설팅의 컨설턴트들이 사장님 말씀도 안 들으니 엔코아 직원이 맞느냐는 것이고, 3) 대한민국은 날짜 타입을 보여주는 방식이 YYYY/MM/DD인데 오라클의 NLS Date 타입이 이것과 달라 날짜를 보여주기 위해서는 Format을 바꿔야 하므로, 이것이 코딩하는데 시간을 많이 잡아먹는다는 것이다.
이 글을 읽는 분들 중에도 위 답변이 당연한 거 아닌가라고 말할지 모르겠다. 그렇다면 이 이야기도 어떤가?
이전 어느 모은행의 프로젝트에서 중요 업무는 메인프레임 기반에서 계층형 DBMS를 사용하고, 일부 업무를 UNIX에 오라클을 사용했다. 어느 날 본사 직원이 데이터 타입이 안 맞는 속성을 발췌해 왔는데 A4 용지로 약 30장에 달하는 속성들이 데이터 타입이 맞지 않는 경우가 있었다. 사연인 즉, PMO 그룹에서 이 은행의 데이터 표준은 메인프레임의 계층형 DBMS가 표준이니 그것에 맞추라고 한 것 때문이었다. PMO 말을 잘 들은 일부 직원들은 오라클을 사용함에도 불구하고 데이터 타입을 계층형 DBMS의 데이터 타입을 사용했고, 반면 오라클을 잘 아는 일부 직원들은 오라클에서 제공하는 데이터 타입을 사용했기 때문에 이러한 일이 발생했던 것이다.
데이터 무결성이 업무 효율성으로 이어진다 관 계형 데이터베이스의 장점 중 하나는 무결성(Integrity)이라는 개념이다. 무결성이란 관계형 연산자를 이용해 데이터가 입력(Insert), 수정(Update), 삭제(Delete), 조회(Select)될 때 데이터 값이 정확성과 일관성을 가져야 되는 업무 규칙(Business Rule)을 말한다.
이러한 무결성 가운데 하나가 속성 무결성 또는 도메인(Domain) 무결성이라는 것이다. 도메인이란 관계형 테이블에 표현되는 속성이 취할 수 있는 값의 집합을 말한다. 예들 들어, 고객명 속성의 데이터 타입을 Varchar2(30)으로 정했다면, 30자리 내에서 문자 값으로 들어올 수 있는 모든 값의 집합이 고객명의 도메인인 것이고, 계약 일자를 Date 타입으로 잡았다면 이 세상에 존재하는 모든 날짜 값의 집합이 계약일자의 도메인인 것이다. 만약에 우리가 계약일자를 Varchar2(8)로 잡았다면 엄밀히 말해서 이는 8자리 내에서 모든 문자 값의 집합이 이 계약일자의 도메인인 것이다.
이러한 개념은 관계형 데이터베이스 이전에는 없던 개념으로 과거에는 모든 데이터의 무결성을 프로그램 로직으로만 해결했다. 프로그램 로직으로 이러한 것을 체크하다 보니 데이터 값이 안 맞아 고생한 경우가 가끔 있었을 것이다. E.F.CODD 박사는 이러한 문제를 해결하고자 DBMS 내에 무결성이라는 개념을 도입해 데이터의 정확성과 일관성을 유지하려고 했던 것이다.
도메인 무결성을 반드시 지켜야 하는 이유를 살펴보면,
첫째, 우리는 도메인을 보고서 의사 결정을 한다는 것이다. 다 시 말하지만 도메인은 속성이 취할 수 있는 모든 값의 집합이라고 했다. 예들 들어, 계약상태라는 속성이 취할 수 있는 값의 집합은 신청, 취소, 유지, 종결의 네 가지가 있다고 할 때, 이 네 가지가 이 속성의 도메인인 것이다. 계약일자는 업무 규칙에서 모든 날짜 집합이 도메인이 될 수 있지만, 계약상태는 업무 규칙에 의거해 이 네 가지 중에 하나만 선택할 수 있는 것이다. 보통 이런 코드 속성은 코드 도메인을 갖는다고 표현하다. 우리는 계약상태의 네 가지 도메인을 보고서 의사 결정을 할 수 있는 것이다.
둘째, 도메인의 중요성은 같은 도메인끼리 비교가 가능하다는 것이다. 현 실 세계에서 예들 들어 보면 형과 아우를 결정할 때 우리는 서로의 나이를 비교해서 결정한다. 나이와 고향을 비교할 수는 없다. 일본사람, 한국사람, 미국사람을 판단할 때는 국적을 가지고 비교하지 다른 어떤 속성으로 비교하지는 않을 것이다. 데이터 모델링에서 고객 테이블에서는 고객번호 속성을 Varchar2(10)로 하고, 계약 테이블에는 고객번호를 Number(10)로 한다면, 이는 비록 값이 같을지라도 DBMS는 다른 도메인으로 인식한다. 이런 경우, DBMS가 비교를 하기 위해서는 같은 도메인이어야 하기 때문에 두 개의 테이블을 조인하는 경우 한 쪽의 도메인(데이터 타입)을 내부에서 바꾼다. 이렇게 되는 경우 잘못하면 DBMS의 옵티마이져가 ACCESS PATH를 잃어버려 FULL TABLE SCAN을 하게 되어 수행속도상에 엄청난 비효율을 유발할 수 있는 것이다.
글 : 장희식_엔코아정보컨설팅 기술상무 금융(은행, 증권, 보험, 종금, 리스 등), 공공, 유통 등 많은 프로젝트에서 데이터 모델링 컨설턴트로써 역할을 수행해 왔으며, 정보 시스템 구현에 있어서 가장 중요한 업무 분석을 어떻게 하면 잘 할 수 있을까를 늘 고민하면서, 이러한 문제를 해결하는데 미력하나마 공헌하고자 데이터 모델링 책을 집필 중이다. 많은 프로젝트에서 고생 하고 있는 선배, 동료, 후배들에게 조금이나마 기여할 수 있는 컨설턴트가 되기를 기원하며 오늘도 프로젝트를 수행중이다.